EAGLE 3.1: Algoritmo que estabiliza la decodificación especulativa en LLMs
Por Redacción Automatización LatAm · 27 de mayo de 2026 · Fuente original: MarkTechPost
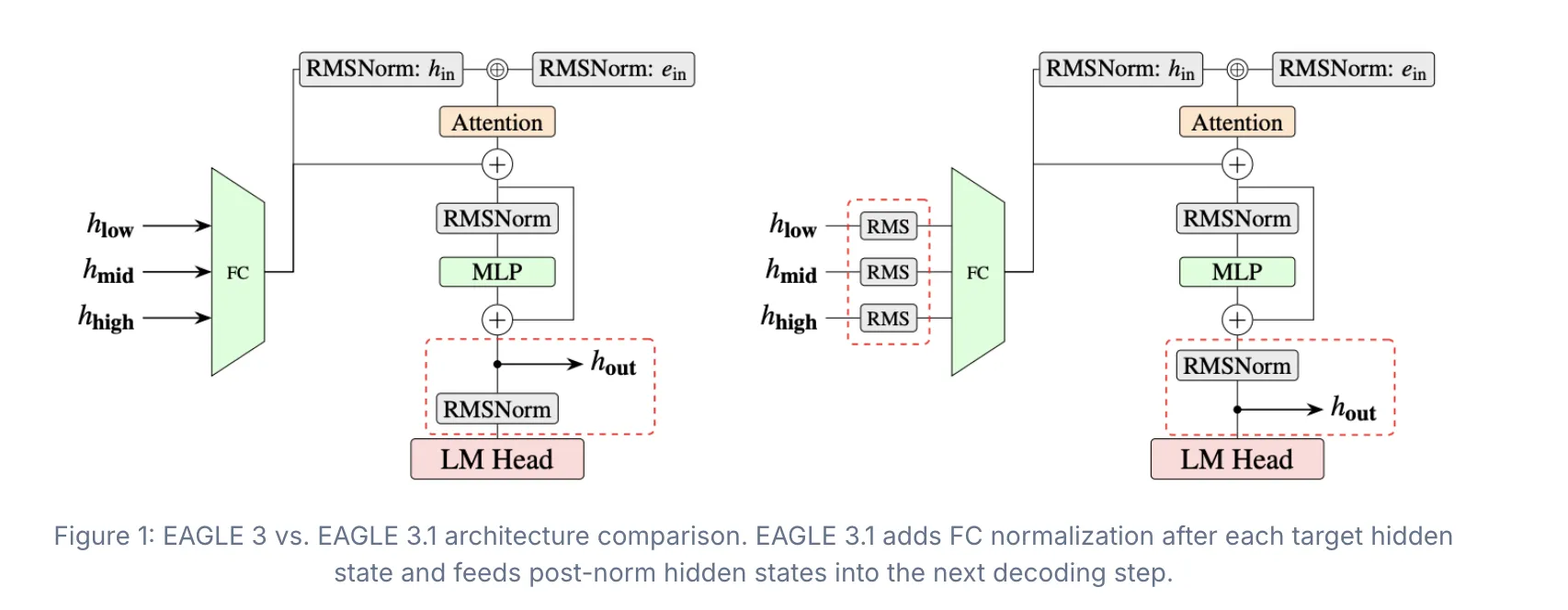
EAGLE 3.1 resuelve problemas de inestabilidad en la decodificación especulativa de modelos de lenguaje grandes. El algoritmo, desarrollado en colaboración entre el equipo EAGLE, vLLM y TorchSpec, corrige la desviación de atención durante la inferencia en entornos de producción.
Contexto del problema
La decodificación especulativa ha emergido como una técnica clave para acelerar la inferencia en modelos de lenguaje grandes, reduciendo significativamente el tiempo de generación de tokens. Sin embargo, implementaciones anteriores presentaban inestabilidades que limitaban su aplicación en ambientes de producción crítica. Cuando los sistemas de control industrial confían en predicciones de LLMs para decisiones automatizadas, esta inestabilidad se traduce en riesgo operacional.
La solución EAGLE 3.1
El algoritmo EAGLE 3.1 aborda específicamente el problema de “attention drift” —desviación en los mecanismos de atención que degrada la precisión de las predicciones durante inferencia especulativa. La colaboración entre el equipo EAGLE, la plataforma vLLM y TorchSpec ha producido una versión mejorada que mantiene la coherencia del modelo incluso bajo cargas de trabajo intensivas.
Esta release busca consolidar la decodificación especulativa como técnica confiable para ambientes de producción, donde la degradación de calidad no es negociable. El enfoque conjunto indica maduración del ecosistema de optimización de LLMs, con herramientas complementarias (vLLM para orquestación de inferencia, TorchSpec para especulación) integrándose en soluciones cohesivas.
Funcionamiento técnico
La desviación de atención ocurre cuando el modelo especulativo y el modelo principal divergen en sus patrones de atención, causando que los tokens predichos no alineen con los que el modelo real generaría. EAGLE 3.1 implementa mecanismos de sincronización mejorados que mantienen la alineación entre componentes, garantizando que las predicciones especulativas permanezcan válidas.
El algoritmo es especialmente relevante para sistemas que requieren alto throughput —como procesamiento de múltiples consultas en paralelo, análisis de logs industriales en tiempo real o generación de reportes automáticos en plataformas MES. Al reducir latencia sin comprometer exactitud, EAGLE 3.1 amplía los casos de uso viables de LLMs en automatización.
Implicaciones para la industria latinoamericana
La infraestructura de IA en LatAm sigue fragmentada: mientras algunos centros de datos cuentan con GPUs de última generación, otros operan con recursos limitados. Optimizaciones como EAGLE 3.1 permiten desplegar LLMs más eficientemente, reduciendo la brecha. Plantas que integran modelos de lenguaje para mantenimiento predictivo, análisis de datos históricos o interfases conversacionales con sistemas SCADA/MES se benefician de latencia predictible.
Además, la estabilidad de EAGLE 3.1 es ventaja competitiva en regulaciones emergentes. A medida que auditorías industriales examinen sistemas basados en IA, la reproducibilidad y confiabilidad de modelos become non-negotiable. Una decodificación especulativa estable facilita certificación y validación de modelos bajo normas como IEC 61508 o ANSI/ISA 84.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
DeepSeek lanza DSpark: framework que acelera generación de texto 60-85%
DeepSeek liberó DSpark, un framework de decodificación especulativa que optimiza el modelo DeepSeek-V4 mediante un módulo de borrador paralelo y verificación adaptativa. La solución logra acelerar la generación de tokens por usuario entre 57-85% sin pérdida de calidad.
Fuente: MarkTechPost
Desvelan el funcionamiento interno de Claude y estrategia de OpenAI
Anthropic logró identificar estructuras ocultas dentro de Claude que revelan cómo el modelo procesa conceptos complejos. Simultáneamente, OpenAI avanza en su estrategia de plataforma integrada.
Fuente: MIT Technology Review
Documentación de planta: la barrera silenciosa para agentes IA
Los sistemas de IA en manufactura enfrentan un obstáculo crítico: la información operativa está atrapada en formatos heredados no estructurados, diseñados para humanos, no para máquinas. Expertos exploran cómo superar esta brecha en AI Manufacturing Day 2026.
Fuente: IIoT World
Cadetes sin experiencia crean apps IA para defensa con ChatGPT
Investigadores del MIT y la Fuerza Aérea estadounidense demostraron que chatbots de IA permiten a militares sin formación técnica desarrollar aplicaciones de software viables adaptadas a sus necesidades operacionales específicas.
Fuente: MIT News — AI
NVIDIA Horizon: Agente IA autonomo para diseño RTL
NVIDIA presenta Horizon, un agente de IA que automatiza el diseño de circuitos RTL mediante repositorios versionados, alcanzando 100% de finalización en benchmarks estándar del sector.
Fuente: MarkTechPost
Microsoft crea división de despliegue de IA con inversión de $2.5B
Microsoft establece una unidad dedicada para implementar soluciones de IA en empresas, siguiendo la estrategia de rivales como Amazon, OpenAI y Anthropic. La inversión busca acelerar la adopción de modelos generativos en la industria.
Fuente: TechCrunch AI