Sakana AI presenta DiffusionBlocks: entrenamiento modular de redes residuales
Por Redacción Automatización LatAm · 28 de mayo de 2026 · Fuente original: MarkTechPost
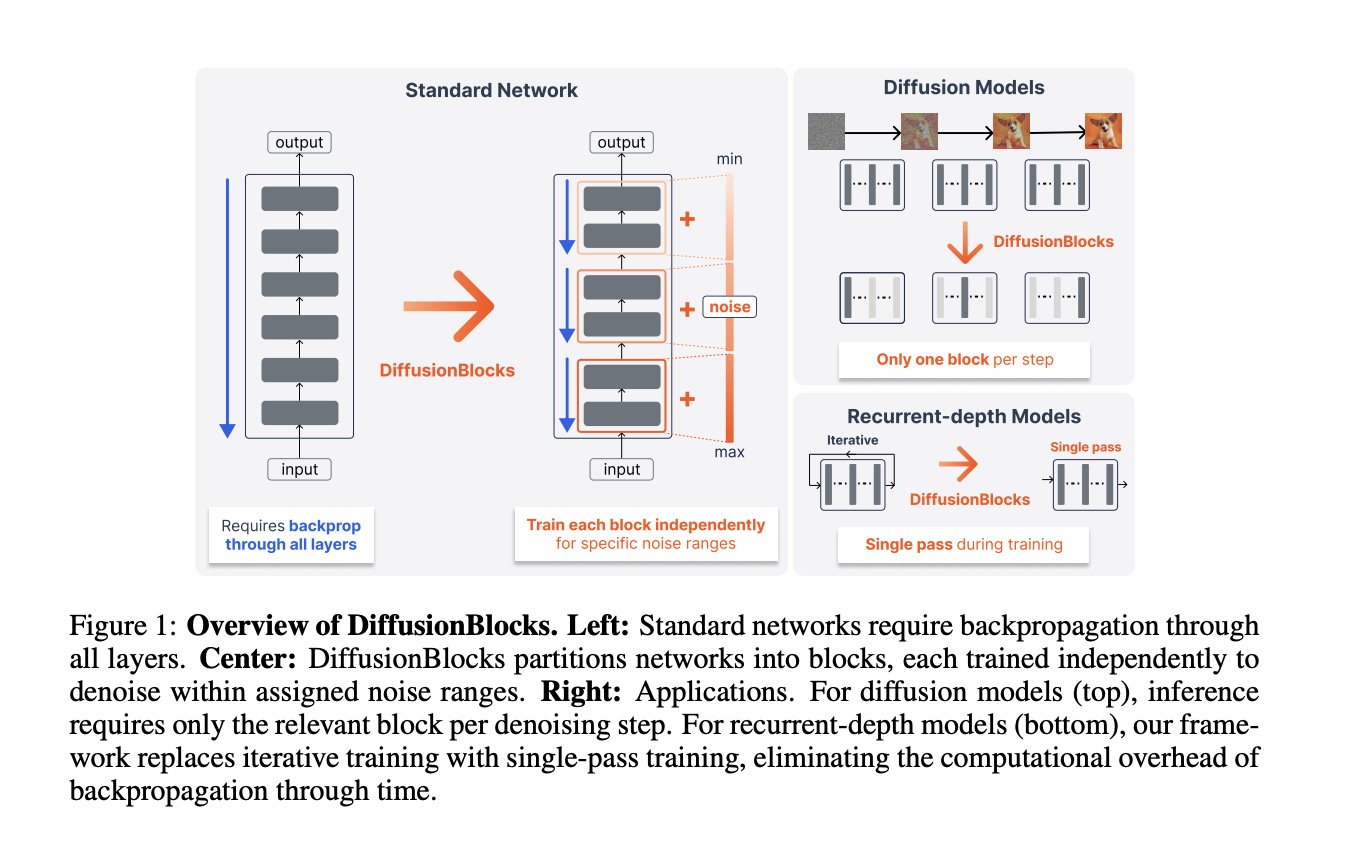
Sakana AI propone DiffusionBlocks, un framework que reinterpreta capas de redes residuales como pasos de desruidación por difusión inversa, permitiendo entrenar bloques de forma independiente y paralela. Esta aproximación promete acelerar el entrenamiento de modelos profundos.
Contexto del problema
El entrenamiento de redes neuronales residuales profundas requiere típicamente propagación hacia atrás secuencial a través de todas las capas, creando dependencias que impiden el paralelismo eficiente. Esta restricción genera cuellos de botella computacionales significativos, especialmente en centros de investigación y empresas de LatAm con recursos GPU limitados.
La propuesta de DiffusionBlocks
Sakana AI introduce una perspectiva innovadora: reinterpretar las actualizaciones de capas en redes residuales como pasos en un proceso de difusión inversa (desruidación). En este marco teórico, cada bloque residual se comporta como un módulo de desruidación independiente, similar a los utilizados en modelos generativos difusivos.
Esta reinterpretación fundamental permite que cada bloque se entrene de manera autónoma, sin necesidad de aguardar a que las capas precedentes completen su actualización. El resultado es un paralelismo a nivel de bloque que antes era imposible en arquitecturas tradicionales.
Detalles técnicos
El framework DiffusionBlocks convierte el problema de optimización secuencial en uno desacoplado. Cada bloque recibe ruido inherente desde las capas anteriores (conceptualmente equivalente al ruido en un paso de difusión) y aprende a refinarlo progresivamente. Las actualizaciones de pesos en un bloque no bloquean el entrenamiento de bloques posteriores, habilitando cómputo concurrente.
Esta arquitectura es compatible con redes residuales existentes (ResNet, DenseNet, y variantes modernas) sin requerir cambios profundos en la estructura base. El entrenamiento puede llevarse a cabo con estrategias de sincronización más laxas, reduciendo overhead de comunicación entre GPUs.
Implicaciones para Latinoamérica
Para la región, esta innovación tiene valor inmediato. Laboratorios de investigación, startups de IA y equipos de manufacturing automation que buscan entrenar modelos de visión computacional para aplicaciones industriales (inspección de calidad, detección de anomalías en líneas de producción) enfrentan restricciones presupuestarias. Un framework que reduzca tiempo de entrenamiento en 30-50% (cifras típicas observadas en métodos de desacoplamiento) permitiría que menos GPUs entrenen modelos comparables a soluciones propietarias.
Asimismo, en plantas manufactureras que adoptan IA para optimización de procesos, la capacidad de entrenar modelos localmente con hardware más modesto aumenta la autonomía operacional y reduce dependencias de servicios cloud externos, mejorando latencia y privacidad de datos sensibles.
El trabajo de Sakana AI también abre conversación sobre arquitecturas de entrenamiento más eficientes globalmente, un área donde instituciones de IA en LatAm pueden contribuir investigación adaptada a restricciones regionales de cómputo.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
Microsoft entrena ventas para posicionar sus modelos IA frente a OpenAI
Microsoft capacita a su equipo comercial para destacar la eficiencia y rentabilidad de sus modelos de IA internos frente a alternativas de OpenAI y Anthropic, buscando incrementar su cuota en el mercado de soluciones generativas.
Fuente: TechCrunch AI
Google lanza LiteRT.js para ejecutar modelos de IA en navegadores web
Google presentó LiteRT.js, una interfaz JavaScript que permite ejecutar modelos de aprendizaje automático directamente en navegadores web con aceleración GPU. La herramienta ofrece mejoras de velocidad de hasta 3x respecto a otros runtimes web, y hasta 60x en procesadores gráficos.
Fuente: MarkTechPost
Métodos de IA para decisiones en tiempo real con recursos limitados
Investigadores del MIT desarrollan técnicas que permiten a modelos de IA tomar decisiones continuas usando recursos computacionales restringidos, abriendo aplicaciones en plantas y sistemas de control industrial.
Fuente: MIT News — AI
Desvelando el razonamiento interno de los modelos IA
Anthropic descubre nuevas formas de acceder a los procesos de razonamiento interno de Claude, abriendo perspectivas sobre cómo estos modelos generativos construyen respuestas. El hallazgo tiene implicaciones para la transparencia y confiabilidad de sistemas IA en aplicaciones críticas.
Fuente: MIT Technology Review
Conocimiento tribal y confianza: claves para IA en manufactura
La adopción de sistemas de IA en plantas requiere capturar el conocimiento acumulado de técnicos experimentados. Ese saber tácito sobre patrones de vibración, desgaste y comportamiento de equipos es tan crítico como los algoritmos modernos.
Fuente: IIoT World
Agentes IA crean espacios virtuales para entrenar robots
Un sistema llamado SceneSmith utiliza agentes de IA colaborativos para generar entornos 3D realistas de espacios cotidianos como cocinas y hoteles, permitiendo que robots simulen tareas domésticas complejas antes de su despliegue.
Fuente: MIT News — AI